이것은 간단한 정규 표현식 일치 함수를 테스트하기 위해 KLEE를 사용하는 예제이다.
소스 트리에서 examples/regexp에 기본 예제를 찾을 수 있다.
Regexp.c에는 간단한 정규 표현식 일치 함수와 KLEE를 사용하여
이 코드를 탐색하기 위해 필요한 기본 테스트 하네스(main())가 포함되어 있다.
소스 코드의 버전을 여기서 볼 수 있다.
이 예제는 KLEE를 사용하여 예제를 빌드하고 실행하는 방법,
그리고 출력을 해석하는 방법과 테스트 드라이버를 수동으로 작성할 때 사용할 수 있는 몇 가지 추가된 KLEE 기능을 보여준다.
먼저 예제를 빌드하고 실행하는 방법,
그리고 테스트 하네스가 어떻게 작동하는지 자세히 설명해보겠다.
예제 빌드하기
첫 번째 단계는 LLVM bitCode 형식의 오브젝트 파일을 생성할 수 있는 컴파일러를 사용하여 소스 코드를 컴파일하는 것이다.
examples/regexp 디렉토리 내에서 다음 명령을 실행하자:
$ clang-11 -I /snap/klee/6/usr/local/include -emit-llvm -c -g -O0 -Xclang -disable-O0-optnone Regexp.c
위 명령을 실행하면, LLVM bitCode 형식의 Regexp.bc 파일이 생성된다.
-I 인수는 컴파일러가 KLEE 가상 머신과 상호 작용하는 데 사용되는 내장 함수에 대한 정의를 포함하는 klee/klee.h 헤더 파일을 찾을 수 있도록 사용된다.
-c는 코드를 네이티브 실행 파일이 아닌 오브젝트 파일로 컴파일하려는 것을 나타내며,
마지막으로 -g는 오브젝트 파일에 추가 디버그 정보를 저장하도록 하며, KLEE가 소스 코드 라인 번호 정보를 나타내기 위해 사용한다.
-O0 -Xclang -disable-O0-optnone은 최적화 없이 컴파일하되, KLEE가 자체 최적화를 수행하지 못하도록 하는 데 사용되었다.
LLVM 도구가 경로에 설치되어 있다면, 이 단계가 작동했는지 생성된 파일에서 llvm-nm을 통해 확인할 수 있다.
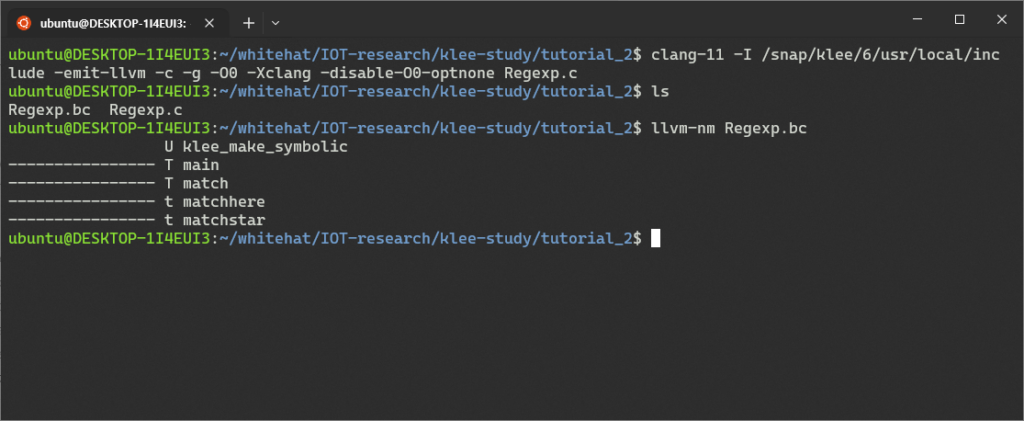
보통 이 프로그램을 실행하기 전에 네이티브 실행 파일을 생성하기 위해 링크해야 할 것이다.
그러나 KLEE는 직접 LLVM 비트코드 파일에서 실행된다.
이 프로그램은 단일 파일만 가지고 있으므로 링크가 필요하지 않다.
여러 입력을 가진 “실제” 프로그램의 경우 일반적인 링크 단계 대신 llvm-link 도구를 사용하여 여러 LLVM 비트코드 파일을 하나의 모듈로 병합하여 KLEE에서 실행할 수 있다.
KLEE를 통해 코드 실행하기
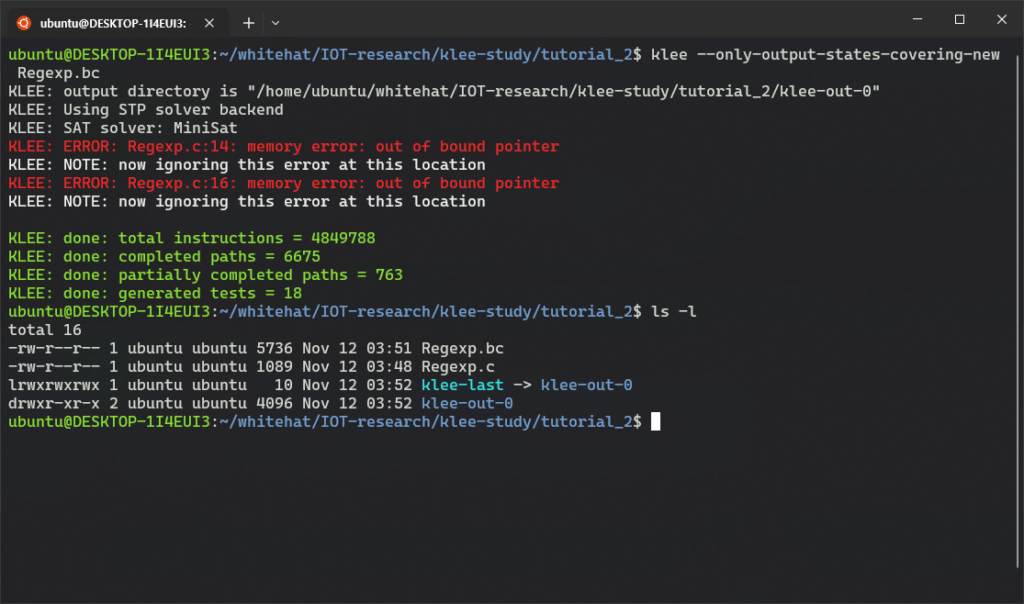
다음 단계는 KLEE를 사용하여 코드를 실행하는 것이다. (명령어의 수는 LLVM 버전 및 최적화 수준에 따라 다를 수 있음)
$ klee --only-output-states-covering-new Regexp.bc KLEE: output directory is "/home/ubuntu/whitehat/IOT-research/klee-study/tutorial_2/klee-out-0" KLEE: Using STP solver backend KLEE: SAT solver: MiniSat KLEE: ERROR: Regexp.c:14: memory error: out of bound pointer KLEE: NOTE: now ignoring this error at this location KLEE: ERROR: Regexp.c:16: memory error: out of bound pointer KLEE: NOTE: now ignoring this error at this location KLEE: done: total instructions = 4849788 KLEE: done: completed paths = 6675 KLEE: done: partially completed paths = 763 KLEE: done: generated tests = 18
KLEE를 시작하면 출력을 저장하는 디렉토리를 표시한다. (ex: klee-out-0)
KLEE는 기본적으로 첫 번째 빈 klee-out-N 디렉토리를 사용하고,
가장 최근에 생성된 디렉토리를 가리키는 klee-last 심볼릭 링크도 만든다.
출력에 사용할 디렉토리를 지정하려면, 명령줄 인수 -output-dir=path를 사용할 수도 있다.
KLEE가 실행 중일 때 “중요한” 이벤트에 대한 상태 메시지를 출력해준다.
예를 들어 프로그램에서 오류를 발견했을 때 메시지가 표시된다.
이 경우 KLEE는 테스트 프로그램의 14번째와 16번째 라인에서 memory error: out of bound pointer (두 개의 잘못된 메모리 액세스)를 감지했다고 나타난다.
이에 대해서는 잠시후 자세히 다시 한번 살펴볼 것이다.
마지막으로, KLEE 실행이 완료되면 실행에 관한 몇 가지 통계를 출력한다.
여기에서 볼 수 있듯이 KLEE는 총 약 4.8 백만 개의 명령어를 실행하고 7,438개의 경로를 탐색하며 16개의 테스트 케이스를 생성해냈다.
KLEE는 새로운 코드를 실제로 포함하는 상태에 대한 테스트 생성을 –only-output-states-covering-new로 제한했기 때문에 16개의 테스트 케이스만 생성했다.
이 플래그를 제외하면 KLEE는 6,677개의 테스트 케이스를 생성할 것이다.
그럼에도 불구하고 KLEE는 모든 경로에 대해 테스트 케이스를 생성하지 않는다.
버그를 발견하면 해당 버그에 도달하는 첫 번째 상태에 대한 테스트 케이스를 생성한다.
해당 위치에서 동일한 버그에 도달하는 다른 모든 경로는 조용히 종료되고 부분적으로 완료된 경로로 보고된다.
오류 케이스의 중복을 신경 쓰지 않는다면, –emit-all-errors 옵션을 사용하여 7,438개의 경로에 대한 테스트 케이스를 생성시킬 수도 있다.
많은 현실적인 프로그램들은 무한하거나(또는 극히 큰) 많은 경로를 가지며, KLEE가 종료되지 않는 것이 일반적이다.
기본적으로 KLEE는 사용자가 Control-C를 누를 때까지 계속 실행된다.(즉, KLEE가 SIGINT를 받을 때까지를 의미)
그러나 KLEE의 실행 시간과 메모리 사용량을 제한하는 부가 옵션들이 존재한다.
- max-time=<시간 간격>: 주어진 시간이 흐른 뒤에는 실행을 중단한다. (eg:
10minor1h5s) - max-forks=N:
N개의 심볼릭 분기 이후에 포크(forking)를 중지하고 남은 경로를 종료한다. - max-memory=N: 메모리 소비를
N메가바이트로 제한시킨다.
KLEE 오류 보고서
KLEE가 실행 중인 프로그램에서 오류를 감지하면 해당 오류를 나타내는 테스트 케이스를 생성하고,
오류의 종류를 식별하는 TYPE과 테스트 케이스 번호인 N을 사용하여 오류에 대한 추가 정보를 testN.TYPE.err 파일에 기록한다.
KLEE가 감지하는 오류 유형 중 일부는 다음과 같다:
- ptr: 유효하지 않은 메모리 위치의 저장 또는 로드
- free: 두 번 호출하거나 유효하지 않은
free() - abort: 프로그램에서
abort()호출 - assert:
assertion실패 - div:
0으로 나누기나 나머지 연산 감지 - user: 입력과 관련된 문제 (유효하지 않은 KLEE 내부 호출) 또는 KLEE 사용 방법에 문제가 있는 경우
- exec: KLEE가 프로그램 실행을 방해하는 문제; 예를 들어 알려지지 않은 명령어, 유효하지 않은 함수 포인터 호출 또는 인라인 어셈블리 호출
- model: KLEE가 완전한 정밀도를 유지하지 못하고 프로그램 상태의 일부만 탐색하는 문제. 예를 들어
malloc에 대한 심볼 크기는 현재 지원되지 않으며, 이러한 경우 KLEE는 인수를 명확하게(concretize)한다.
KLEE는 오류를 감지하면 콘솔에 메시지를 출력해준다.
위의 테스트 실행에서 KLEE가 두 개의 메모리 오류를 감지했음을 확인할 수 있다.
모든 프로그램 오류에 대해 KLEE는 .err 파일에 간단한 백트레이스(backtrace)를 기록한다.
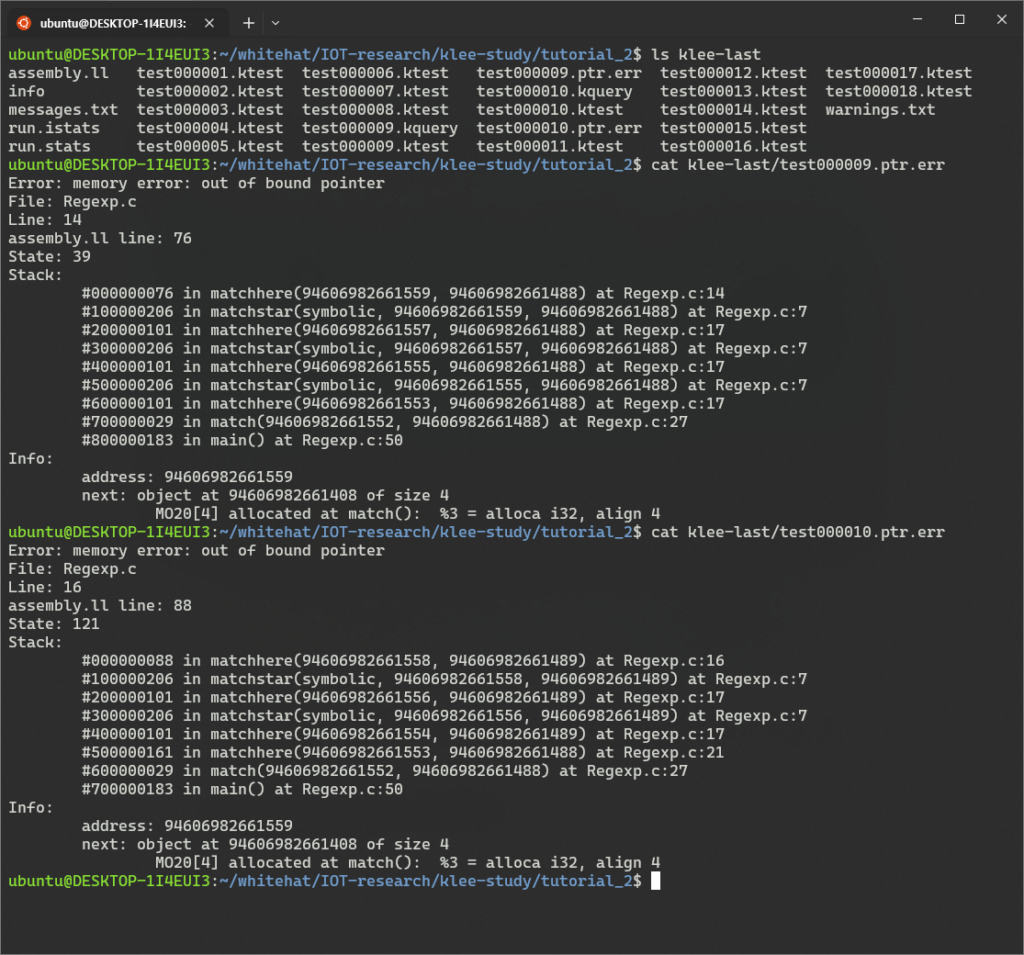
아래는 위에서 언급한 오류 중 하나의 모습이다.
Error: memory error: out of bound pointer
File: Regexp.c
Line: 14
assembly.ll line: 76
State: 39
Stack:
#000000076 in matchhere(94606982661559, 94606982661488) at Regexp.c:14
#100000206 in matchstar(symbolic, 94606982661559, 94606982661488) at Regexp.c:7
#200000101 in matchhere(94606982661557, 94606982661488) at Regexp.c:17
#300000206 in matchstar(symbolic, 94606982661557, 94606982661488) at Regexp.c:7
#400000101 in matchhere(94606982661555, 94606982661488) at Regexp.c:17
#500000206 in matchstar(symbolic, 94606982661555, 94606982661488) at Regexp.c:7
#600000101 in matchhere(94606982661553, 94606982661488) at Regexp.c:17
#700000029 in match(94606982661552, 94606982661488) at Regexp.c:27
#800000183 in main() at Regexp.c:50
Info:
address: 94606982661559
next: object at 94606982661408 of size 4
MO20[4] allocated at match(): %3 = alloca i32, align 4
백트레이스의 각 줄은 프레임 번호, 명령어 라인 (이것은 실행 출력과 함께 찾을 수 있는 assembly.ll 파일에서의 라인 번호를 의미함), 함수와 인수 (구체적인 매개변수의 값을 포함함), 그리고 소스 정보를 나열한다.
특정 오류 보고서에는 추가 정보도 포함될 수 있다.
메모리 오류의 경우, KLEE는 잘못된 주소를 표시하고 해당 주소 앞뒤의 힙(heap)에 있는 객체를 보여준다.
이 경우 주소가 바로 이전 객체의 끝에서 한 바이트 뒤에 있는 것으로 나타난다.
테스트 하네스를 변경하기
이 프로그램에서 KLEE가 메모리 오류를 찾는 이유는 정규 표현식 함수에 버그가 있는 것이 아니라 테스트 드라이버에 문제가 있다는 것을 나타낸다.
문제는 입력 정규 표현식 버퍼를 완전히 심볼릭하게 만들고 있지만, match 함수는 해당 버퍼가 널 종료된 문자열이어야 한다고 예상한다.
따라서 이 문제를 해결하는 2가지 방법을 살펴보겠다.
가장 간단한 방법은 버퍼를 심볼릭하게 만든 후에 \0을 버퍼 끝에 저장하는 것이다.
이렇게 하면 우리의 드라이버는 다음과 같다:
int main() {
// The input regular expression.
char re[SIZE];
// Make the input symbolic.
klee_make_symbolic(re, sizeof re, "re");
re[SIZE - 1] = '\\0';
// Try to match against a constant string "hello".
match(re, "hello");
return 0;
}
버퍼를 심볼릭하게 만드는 것은 내용을 심볼 변수를 참조하도록 초기화하는 것뿐이며, 여전히 원하는 대로 메모리를 수정할 수 있다.
이 테스트 프로그램을 다시 컴파일하고 KLEE에서 실행하면 메모리 오류가 사라질 것이다.
동일한 효과를 얻기 위한 다른 방법은 klee_assume 내장 함수를 사용하는 것이다.
klee_assume은 일반적으로 조건식을 인수로 사용하며, 현재 경로에서 해당 표현식이 참이라고 “가정”한다. (표현식이 절대로 발생하지 않을 경우, 즉 표현식이 확실히 거짓인 경우, KLEE는 오류를 보고함)
우리는 klee_assume을 사용하여 문자열이 널 종료될 경우에만 상태를 탐색하도록 하기 위해 드라이버를 다음과 같이 작성할 수 있다:
int main() {
// The input regular expression.
char re[SIZE];
// Make the input symbolic.
klee_make_symbolic(re, sizeof re, "re");
klee_assume(re[SIZE - 1] == '\\0');
// Try to match against a constant string "hello".
match(re, "hello");
return 0;
}
이 특정 예제에서는 두 가지 솔루션이 모두 잘 작동하지만, 일반적으로 klee_assume 방식이 더 유연하다:
- 제약 조건을 명시적으로 선언함으로써, 이것은 테스트 케이스가
\0을 가져야 함을 강제한다.
첫 번째 예제에서 종료 널을 명시적으로 쓰는 경우, 심볼릭 입력의 마지막 바이트가 무엇이든 상관하지 않으며 KLEE는 아무 값이든 생성해낼 수 있다.
테스트 케이스를 직접 검토해야 하는 경우, 중요한 모든 값을 표시하도록 하는 것이 더 편리할 수도 있다. - klee_assume을 사용하면 더 복잡한 제약 조건을 인코딩할 수 있다.
예를 들어, klee_assume(re[0] != ‘^’)를 사용하여 첫 번째 바이트가^가 아닌 상태만을 탐색하도록 KLEE에 지시할 수 있다.
참고
klee_assume을 여러 조건과 함께 사용할 때 주의해야 한다.
&& 및 ||과 같은 Boolean 조건은 표현식의 결과를 계산하기 전에 코드로 컴파일될 수 있다.
이러한 상황에서 KLEE는 klee_assume 호출에 도달하기 전에 프로세스를 분기할 것이며, 불필요한 추가 상태를 탐색할 수 있다.
이러한 이유로 klee_assume에 가능한 간단한 표현식을 사용하는 것이 좋으며 (ex: 단일 호출을 여러 호출로 분할),
단축 평가(short-circuiting) 연산자 대신 & 및 | 연산자를 사용하는 것이 좋다.